Python应用于爬虫领域业界已经相当的广泛了,今天就采用urllib + re 爬取下百度国内即时新闻。
软件环境
Python : 3.6.0
PyCharm: Community 2017.2
Python 下载地址
Pycharm 下载地址(Community是免费的)
主要思路
采用urllib请求制定url,拿到网页的html,然后采用re进行正则匹配找到新闻标题
爬取过程
1. 导入urllib 和 re 两个模块
import urllib
from urllib import request
import re
2. 采用urllib.request.urlopen 打开百度信息url,并取得所有html
url = "http://news.baidu.com/guonei"
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
urllib.urlopen()方法用于打开一个url地址。
read()方法用于读取URL上的数据,并把整个页面下载下来。 #### 3. 在Chrome中按F12可以查看到网页的源代码,可以看到新闻位于 div id="instant-news"下面
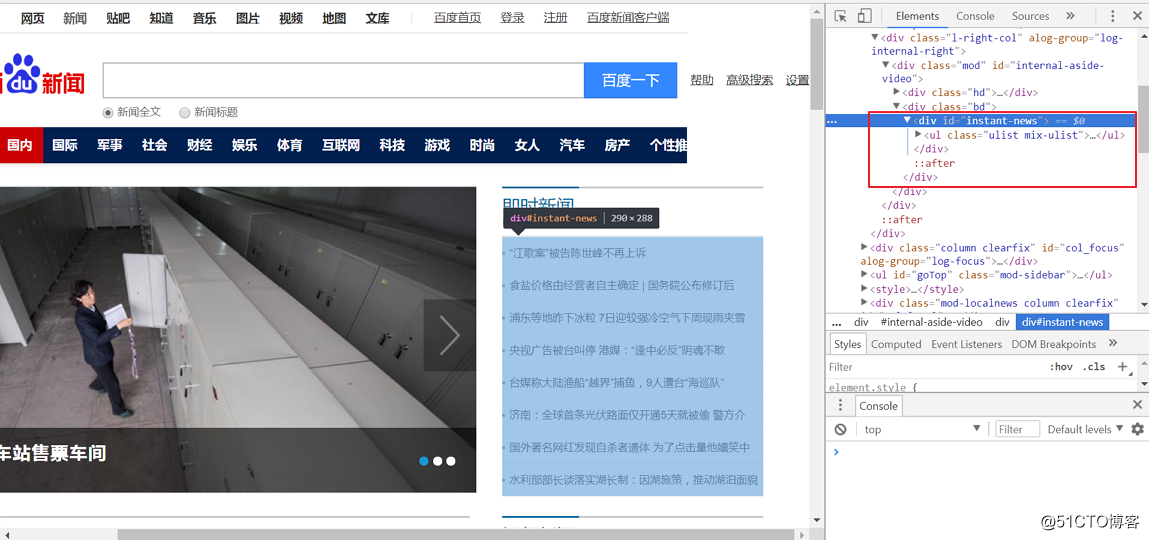
4. 获取即时信息的整个div的html并存储到变量: instant_news_html
pattern_of_instant_news = re.compile('<div id="instant-news.*?</div>',re.S)
instant_news_html = re.findall(pattern_of_instant_news, html)[0]
5. 从全部news的html中匹配出每一个新闻标题
pattern_of_news = re.compile('<li><a.*?>(.*?)</a></li>', re.S)
news_list = re.findall(pattern_of_news, instant_news_html)
for news in news_list:
print(news)
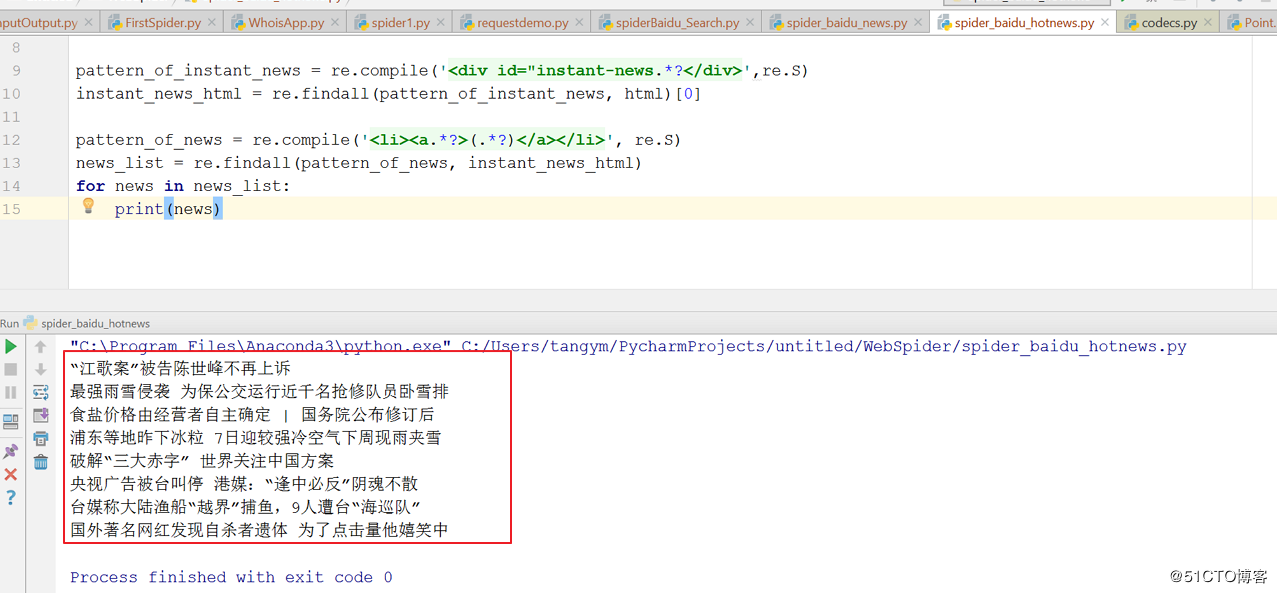
将会看到如入结果
完整源代码
import urllib
from urllib import request
import re
url = "http://news.baidu.com/guonei"
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
pattern_of_instant_news = re.compile('<div id="instant-news.*?</div>',re.S)
instant_news_html = re.findall(pattern_of_instant_news, html)[0]
pattern_of_news = re.compile('<li><a.*?>(.*?)</a></li>', re.S)
news_list = re.findall(pattern_of_news, instant_news_html)
for news in news_list:
print(news)